Introduction and Motivation
-
Purpose: Find stationary points of smooth functions
-
Approach: Use second-order Taylor approximation
-
Key Idea: Approximate function locally by quadratic and minimize exactly
-
Advantages:
-
Quadratic convergence near solution
-
Scale-invariant
-
Natural for optimization problems
-
-
Disadvantages:
-
Requires Hessian computation
-
May not converge globally
-
Expensive per iteration
-
Historical Context
-
Isaac Newton (1643-1727): Original method for root finding
-
Joseph Raphson (1648-1715): Improved formulation
-
Extension to Optimization:
-
Apply Newton-Raphson to \(\nabla f(x) = 0\)
-
Use second derivatives (Hessian matrix)
-
-
Modern Development:
-
Convergence analysis (20th century)
-
Globalization strategies
-
Computational considerations
-
Mathematical Foundation
For a twice continuously differentiable function \(f: \mathbb{R}^n \to \mathbb{R}\):
Second-Order Taylor Expansion
Where:
-
\(\nabla f(x)\) is the gradient vector
-
\(\nabla^2 f(x)\) is the Hessian matrix
-
\(p\) is the step vector
Key Insight: Minimize the quadratic approximation to find the step direction.
Deriving Newton’s Step
Let \(m_k(p) = f(x_k) + \nabla f(x_k)^T p + \frac{1}{2} p^T \nabla^2 f(x_k) p\)
To minimize \(m_k(p)\), set \(\nabla_p m_k(p) = 0\):
Newton’s Step
Requirements:
-
\(\nabla^2 f(x_k)\) must be invertible
-
Typically assume \(\nabla^2 f(x_k) \succ 0\) (positive definite)
Newton’s Method Algorithm
- Input: Starting point \(x_0\), tolerance \(\epsilon > 0\)
- Set \(k = 0\)
- While \(\|\nabla f(x_k)\| > \epsilon\):
- Compute gradient \(g_k = \nabla f(x_k)\)
- Compute Hessian \(H_k = \nabla^2 f(x_k)\)
- If \(H_k\) is not positive definite:
- Apply modification (e.g., add \(\lambda I\))
- Solve \(H_k p_k = -g_k\) for \(p_k\)
- Set \(x_{k+1} = x_k + p_k\)
- \(k = k + 1\)
- Output: \(x_k\) (approximate minimizer)
Convergence Analysis
Local Quadratic Convergence
Let \(f: \mathbb{R}^n \to \mathbb{R}\)be twice continuously differentiable. Suppose \(x^*\) is a local minimizer where:
-
\(\nabla f(x^*) = 0\)
-
\(\nabla^2 f(x^*)\) is positive definite
Then there exists \(\delta > 0\) such that if \(\|x_0 - x^*\| < \delta\), Newton’s method converges quadratically:
for some constant \(C > 0\).
Interpretation: Near the solution, errors square at each iteration!
Convergence Rate Comparison

Note: Newton’s method achieves superlinear convergence even when convergence conditions are relaxed.
Global Convergence Issues
Problems with Pure Newton’s Method:
-
Non-convex functions: May converge to saddle points or maxima
-
Indefinite Hessian: \(\nabla^2 f(x_k)\) not positive definite
-
Poor starting point: May diverge or converge slowly
-
Singular Hessian: \(\nabla^2 f(x_k)\) not invertible
Example: Divergence
Consider \(f(x) = x^3\). Starting from \(x_0 = 1\):
Converges to \(x = 0\), but \(f'(0) = 0\) and \(f''(0) = 0\) (not a minimum!)
Practical Implementations
Problem: \(\nabla^2 f(x_k)\) may not be positive definite
Solutions:
-
Modified Newton Method:
Choose \(\lambda_k\) to ensure positive definiteness\[H_k + \lambda_k I \succ 0\] -
Eigenvalue Modification:
\[H_k = Q \Lambda Q^T \rightarrow Q |\Lambda| Q^T\]Replace negative eigenvalues with their absolute values
-
Cholesky with Pivoting: Add regularization during factorization
Trade-off: Modifications may slow convergence but ensure descent direction.
Line Search Newton Method
Globalization Strategy: Combine Newton direction with line search
- Compute Newton step \(p_k = -H_k^{-1} g_k\)
- If \(p_k\) is not a descent direction:
- Modify \(H_k\) or use steepest descent
- Choose step size \(\alpha_k\) via line search:
- \(f(x_k + \alpha_k p_k) < f(x_k) + c_1 \alpha_k g_k^T p_k\)
- Set \(x_{k+1} = x_k + \alpha_k p_k\)
Benefits:
-
Guarantees decrease in function value
-
Global convergence under mild conditions
-
Preserves quadratic convergence near solution
Computational Considerations
Cost per Iteration:
-
Gradient computation: \(O(n)\) (usually)
-
Hessian computation: \(O(n^2)\) storage, varies in time
-
Linear system solution: \(O(n^3)\) (dense) or \(O(n^{1.5})\) (sparse)
Hessian Computation Methods:
-
Analytical: Exact but may be complex to derive
-
Finite Differences:
\[\frac{\partial^2 f}{\partial x_i \partial x_j} \approx \frac{f(x + h e_i + h e_j) - f(x + h e_i) - f(x + h e_j) + f(x)}{h^2}\] -
Automatic Differentiation: Efficient and exact
Linear System Solution: Use Cholesky decomposition when \(H \succ 0\)
Examples and Applications
Consider \(f(x) = \frac{1}{2} x^T Q x - b^T x\) where \(Q \succ 0\).
-
\(\nabla f(x) = Qx - b\)
-
\(\nabla^2 f(x) = Q\)
Newton step: \(p_k = -Q^{-1}(Qx_k - b) = Q^{-1}b - x_k\)
Update: \(x_{k+1} = x_k + p_k = Q^{-1}b\)
Result
Newton’s method finds the exact solution in one iteration for quadratic functions!
This is why quadratic convergence is optimal near the solution.
Example 2: Rosenbrock Function
Minimum at \((1, 1)\) with \(f(1, 1) = 0\).
Gradient:
Hessian:
Challenge: Hessian can be indefinite far from solution, requiring modifications.
Applications
Newton’s Method is Essential in:
-
Machine Learning:
-
Logistic regression (IRLS algorithm)
-
Neural network training (second-order methods)
-
Support vector machines
-
-
Statistics:
-
Maximum likelihood estimation
-
Generalized linear models
-
Bayesian inference (MAP estimation)
-
-
Engineering:
-
Structural optimization
-
Control system design
-
Signal processing
-
-
Economics and Finance:
-
Portfolio optimization
-
Option pricing models
-
Equilibrium analysis
-
Advantages and Limitations
-
Quadratic Convergence: Extremely fast near solution
-
Scale Invariance: Performance independent of problem scaling
-
Affine Invariance: Unaffected by linear transformations
-
Natural for Optimization: Derived from optimization principles
-
Exact for Quadratics: Optimal for quadratic functions
-
Well-Understood Theory: Extensive convergence analysis
When to Use Newton’s Method
-
High accuracy required
-
Hessian computation is feasible
-
Problem is well-conditioned
-
Good starting point available
Limitations and Disadvantages
-
Computational Cost: \(O(n^3)\) per iteration
-
Memory Requirements: \(O(n^2)\) for Hessian storage
-
Hessian Computation: May be difficult or expensive
-
Global Convergence: No guarantee without modifications
-
Indefinite Hessian: Requires special handling
-
Singular Points: May fail at saddle points
When NOT to Use Newton’s Method
-
Large-scale problems (\(n > 10^4\))
-
Noisy or discontinuous functions
-
When only low accuracy is needed
-
Hessian is unavailable or expensive
Variants and Extensions
-
Damped Newton Method:
\[x_{k+1} = x_k - \alpha_k H_k^{-1} g_k\]Use line search to choose \(\alpha_k\)
-
Trust Region Newton:
subject to \(\|p\| \leq \Delta_k\)\[\min_{p} \nabla f(x_k)^T p + \frac{1}{2} p^T \nabla^2 f(x_k) p\] -
Quasi-Newton Methods: Approximate Hessian with updates (BFGS, L-BFGS)
-
Gauss-Newton: For nonlinear least squares problems
-
Levenberg-Marquardt: Combines Gauss-Newton with steepest descent
Relationship to Other Methods
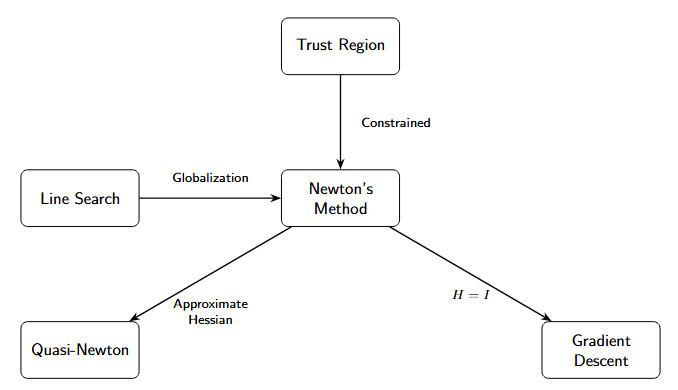
Newton’s method serves as the foundation for many advanced optimization algorithms.
Conclusion
Key Takeaways:
-
Newton’s method uses second-order information for fast convergence
-
Achieves quadratic convergence near the solution
-
Requires positive definite Hessian for guaranteed descent
-
Computational cost is \(O(n^3)\) per iteration
-
Global convergence requires modifications (line search, trust region)
-
Exact solution for quadratic functions in one step
-
Foundation for many modern optimization algorithms
Practical Advice
Use Newton’s method when high accuracy is needed and Hessian computation is feasible. For large problems, consider quasi-Newton alternatives.
Further Reading
Recommended Textbooks:
-
Nocedal & Wright: Numerical Optimization
-
Boyd & Vandenberghe: Convex Optimization
-
Bertsekas: Nonlinear Programming
Next Topics:
-
Quasi-Newton Methods (BFGS, L-BFGS)
-
Trust Region Methods
-
Constrained Optimization (KKT conditions)
-
Interior Point Methods